 SpringBoot整合Elasticsearch Rest Client
SpringBoot整合Elasticsearch Rest Client
# 前言
前面通过nginx搭建了ik分词器的自定义词库,接下来就用SpringBoot整合Elasticsearch Rest Client。
当在电商商品页面场景时,需要发请求到Spinrgboot,Spirngoobt操作ES,再用ES来检索商品,将处理的结果返回到前端页面。
对于Java来操作ES有两种方式:
9300 TCP。
(ES集群节点之间通信也是用9300端口)如果使用这种方式,就需要与ES建立一个常链接,而支持这种操作需要用
spring-data-elasticsearch-transport-api.jar,包括官方的elasticsearch.jar也支持这种操作。但是不建议使用9300 TCP端口来操作,因为Spirngboot版本不同,transport-api.jar不同,不能适配es版本,而且连官方也说,elasticsearch 7.x已经不建议使用,8.x版本以上都要废弃使用
spring-data-elasticsearch-transport-api.jar来操作ESspring-data-elasticsearch-transport-api.jar目前最多支持到elasticsearch 6.3.8版本
9200 HTTP
就是给ES发送请求,市面上有许多方式:
- JestClinet
非官方,更新慢,maven仓库 (opens new window)最近一次更新是2018年的,而且最多支持elasticsearch 6.3.1版本。
- RestTemplate
模拟法HTTP请求,ES很多操作需要自己封装,如果自己操作Query DSL就需要自己封装,比较麻烦。
- HttpClient
同上
- Elasticssearch-Rest-Client
官方的RestClient,封装了ES操作,API层次分明,上手简单。而且还支持Java,Javascript,Go,Ruby,Python,.net,PHP等等各种语言来操作
所以优先选择官方的RestClient。
为什么不用js来给ES发送请求?
因为安全问题,ES一般部署在集群服务器上,端口不对外暴露,一旦保留了容易被人恶意利用。而且如果用JS发送请求给ES,根本不需要用到RestClient,直接发送请求就可以了。
# Java REST Client
The Java REST Client comes in 2 flavors:
- Java Low Level REST Client (opens new window): the official low-level client for Elasticsearch. It allows to communicate with an Elasticsearch cluster through http. Leaves requests marshalling and responses un-marshalling to users. It is compatible with all Elasticsearch versions.
- Java High Level REST Client (opens new window): the official high-level client for Elasticsearch. Based on the low-level client, it exposes API specific methods and takes care of requests marshalling and responses un-marshalling.
Elasticssearch-Rest-Client,分高低阶两种:
他们的关系就类似于mybatis(高阶)与JDBC(低阶)的关系一样,mybatis封装jdbc,再来操作数据库就简单了,所以要用Java High Level REST Client (opens new window)。
# 实现方式
现在直接用idea新建一个独立项目来检索ES。
# 创建独立项目
- new moudle,选择spring初始化向导
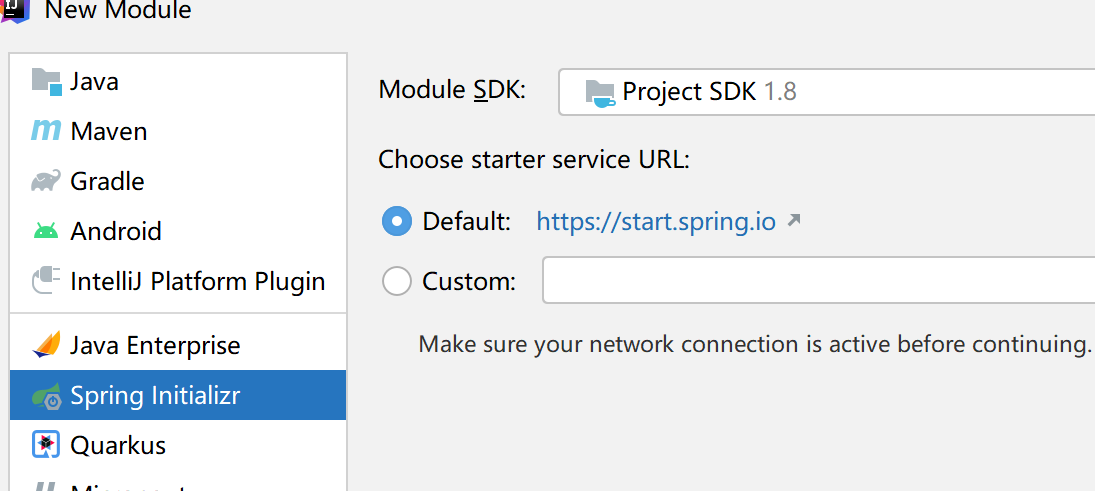
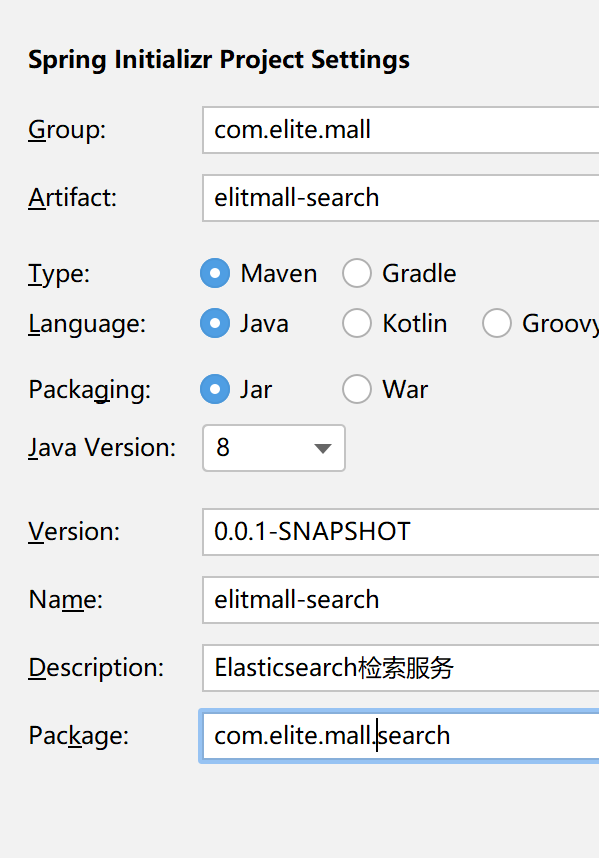
- 组件 选Web下的SpringWeb
# 导入maven依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.10.0</version>
</dependency>
2
3
4
5
这里改为当前ES的版本,不一定是7.10.0
导入依赖完成,查看一下
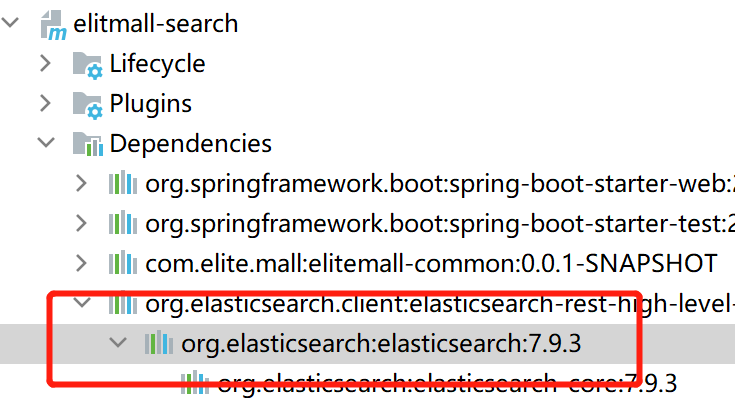
这里发现,Springboot默认导入的ES版本与我虚拟机中ES版本的不一致。所以需要在search微服务的pom文件指定版本,保持和虚拟机中的一致。
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.6.2</elasticsearch.version>
</properties>
2
3
4
改完后,刷新maven,查看ES版本是否一致。
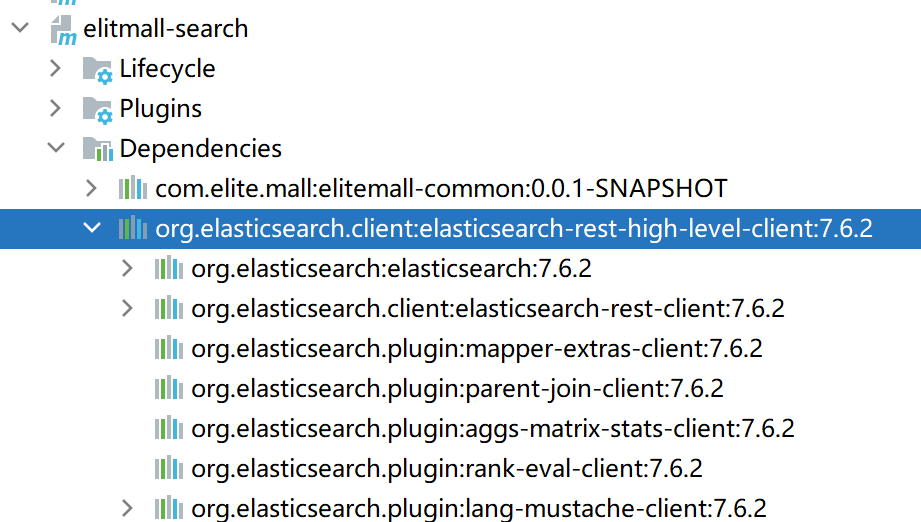
导入成功后,再导入自己微服务的公共common模块。
# 注册到注册中心
elitmall-search/src/main/resources/application.properties
spring.cloud.nacos.discovery.server-addr=127.0.0.1:8848
spring.application.name=elitmall-search
2
启动类添加@EnableDiscoveryClient
package com.elite.mall.search;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
@EnableDiscoveryClient
@SpringBootApplication
public class ElitmallSearchApplication {
public static void main(String[] args) {
SpringApplication.run(ElitmallSearchApplication.class, args);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 编写ES配置
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http"),
new HttpHost("localhost", 9201, "http")));
2
3
4
实际代码:
package com.elite.mall.search.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ElasticsearchConfig {
@Bean
public RestHighLevelClient esRestClient() {
RestClientBuilder builder = RestClient.builder(new HttpHost("192.168.56.10", 9200, "http"));
RestHighLevelClient client = new RestHighLevelClient(builder);
return client;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 新建测试案例
package com.elite.mall.search.config;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
class ElasticsearchConfigTest {
@Autowired
private RestHighLevelClient esClient;
@Test
void esRestClient() {
System.out.println(esClient);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
结果返回null,检查了以前的测试案例,发现缺少@SpringBootTest
package com.elite.mall.search.config;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
class ElasticsearchConfigTest {
@Autowired
private RestHighLevelClient esClient;
@Test
void esRestClient() {
System.out.println(esClient);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
结果还是报错,没有指定数据源,因为我common模块设置了数据源
Caused by: org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'scopedTarget.dataSource' defined in class path resource
修改启动类,排除数据源
package com.elite.mall.search;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
@EnableDiscoveryClient
@SpringBootApplication(exclude = DataSourceAutoConfiguration.class)
public class ElitmallSearchApplication {
public static void main(String[] args) {
SpringApplication.run(ElitmallSearchApplication.class, args);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
重新运行测试案例,测试案例返回:
org.elasticsearch.client.RestHighLevelClient@2e62ead7
测试通过,能打印这个对象。接下来就可以通过官方文档操作ES,进行增删改查操作了。。
# 请求设置
All APIs in the
RestHighLevelClientaccept aRequestOptionswhich you can use to customize the request in ways that won’t change how Elasticsearch executes the request. For example, this is the place where you’d specify aNodeSelectorto control which node receives the request. See the low level client documentation (opens new window) for more examples of customizing the options.
在进行增删改查之前,必须先了解RequestOptions,比如ES添加了安全访问规则,所有请求访问ES,都必须带上一个安全头等一些设置的信息,那么就可以通过RequestOptions来对所有请求来进行一个统一的设置,这个设置设置是来参考低版本客户端的文档 (opens new window)。
The
RequestOptionsclass holds parts of the request that should be shared between many requests in the same application. You can make a singleton instance and share it between all requests:
private static final RequestOptions COMMON_OPTIONS;
static {
RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();
builder.addHeader("Authorization", "Bearer " + TOKEN);
builder.setHttpAsyncResponseConsumerFactory(
new HttpAsyncResponseConsumerFactory
.HeapBufferedResponseConsumerFactory(30 * 1024 * 1024 * 1024));
COMMON_OPTIONS = builder.build();
}
2
3
4
5
6
7
8
9
官方建议RequestOptions做成一个单实例,所有请求设置共享使用。
比如可以带上自己的令牌,自定义响应的消费者。
@Configuration
public class ElasticsearchConfig {
public static final RequestOptions COMMON_OPTIONS;
static {
RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();
// builder.addHeader("Authorization", "Bearer " + TOKEN);
// builder.setHttpAsyncResponseConsumerFactory(
// new HttpAsyncResponseConsumerFactory
// .HeapBufferedResponseConsumerFactory(30 * 1024 * 1024 * 1024));
COMMON_OPTIONS = builder.build();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
为了方便我测试增删改查,先把所有请求头,token,令牌时间注释掉,并且改为public。以后有需要再进行修改。
# Index 索引存储数据
参照官方文档 (opens new window),首先要构造一个请求,posts指的是在这个索引。
IndexRequest request = new IndexRequest("posts");
然后编写数据,存储数据方式,有很多种:
- json字符串
- 哈希表Mapping
XContentBuilderobject- key-pairs,String键值对
数据的id,可以不设置,不设置就会默认自动生成。
在实际场景中,显然是json字符串是最常用的。
存储完数据后,可以设置版本、超时时间等等,最后通过同步执行或异步执行来执行保存。
- 同步保存
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
- 异步保存
client.indexAsync(request, RequestOptions.DEFAULT, listener);
# 测试案例
@Test
void indexData() throws IOException {
IndexRequest indexRequest = new IndexRequest("user");
indexRequest.id("1");
//indexRequest.source("username", "zhangsan", "age", 18, "gender", "男");
User user = new User();
user.setUsername("zhangsan");
user.setAge(18);
user.setGender("男");
String jsonString = JSON.toJSONString(user);
// 要保存的内容
indexRequest.source(jsonString, XContentType.JSON);
// 执行保存操作
IndexResponse index = esClient.index(indexRequest, ElasticsearchConfig.COMMON_OPTIONS);
// 提取有用的响应数据
System.out.println(index);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 最后输出
IndexResponse[index=user,type=_doc,id=1,version=1,result=created,seqNo=0,primaryTerm=1,shards={"total":2,"successful":1,"failed":0}]
2
# kibana 查询
GET user/_search
# 返回
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "user",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"age" : 18,
"gender" : "男",
"username" : "zhangsan"
}
}
]
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
当我把username改为lisi时,发现测试案例也可以通过,这次就变成更新操作了。
# 输出结果
IndexResponse[index=user,type=_doc,id=1,version=2,result=updated,seqNo=1,primaryTerm=1,shards={"total":2,"successful":1,"failed":0}]
# Kibana查询返回
{
"took" : 262,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "user",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"age" : 18,
"gender" : "男",
"username" : "lisi"
}
}
]
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
其他增删改查操作,这里就不展开了,可以参考官方文档 (opens new window)。
# 复杂检索 Search
参照官方文档 (opens new window),有一个检索示例:
SearchRequest searchRequest = new SearchRequest();
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
searchRequest.source(searchSourceBuilder);
2
3
4
构造一个检索请求
构建
Query DSL
但是上面的操作,并不会执行检索,执行检索需要手动进行。
执行检索也分同步和异步操作:
- 同步:
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
- 异步:
client.searchAsync(searchRequest, RequestOptions.DEFAULT, listener);
# 测试案例1
@Test
void searchData() throws IOException {
// 创建检索请求
SearchRequest searchRequest = new SearchRequest();
// 指定索引
searchRequest.indices("bank");
// 指定DSL,检索条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("address", "mill"));
System.out.println(searchSourceBuilder);
// searchSourceBuilder.from();
// searchSourceBuilder.size();
// searchSourceBuilder.aggregation();
searchRequest.source(searchSourceBuilder);
// 执行检索
SearchResponse searchResponse = esClient.search(searchRequest, RequestOptions.DEFAULT);
// 分析结果
System.out.println(searchResponse.toString());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
- 条件构造
{
"query": {
"match": {
"address": {
"query": "mill",
"operator": "OR",
"prefix_length": 0,
"max_expansions": 50,
"fuzzy_transpositions": true,
"lenient": false,
"zero_terms_query": "NONE",
"auto_generate_synonyms_phrase_query": true,
"boost": 1.0
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
其中boost是来表示关联相关性得分,具体可以参照官方文档 (opens new window)。
- 返回
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 5.4032025,
"hits": [{
"_index": "bank",
"_type": "account",
"_id": "970",
"_score": 5.4032025,
"_source": {
"account_number": 970,
"balance": 19648,
"firstname": "Forbes",
"lastname": "Wallace",
"age": 28,
"gender": "M",
"address": "990 Mill Road",
"employer": "Pheast",
"email": "forbeswallace@pheast.com",
"city": "Lopezo",
"state": "AK"
}
}, {
"_index": "bank",
"_type": "account",
"_id": "136",
"_score": 5.4032025,
"_source": {
"account_number": 136,
"balance": 45801,
"firstname": "Winnie",
"lastname": "Holland",
"age": 38,
"gender": "M",
"address": "198 Mill Lane",
"employer": "Neteria",
"email": "winnieholland@neteria.com",
"city": "Urie",
"state": "IL"
}
}, {
"_index": "bank",
"_type": "account",
"_id": "345",
"_score": 5.4032025,
"_source": {
"account_number": 345,
"balance": 9812,
"firstname": "Parker",
"lastname": "Hines",
"age": 38,
"gender": "M",
"address": "715 Mill Avenue",
"employer": "Baluba",
"email": "parkerhines@baluba.com",
"city": "Blackgum",
"state": "KY"
}
}, {
"_index": "bank",
"_type": "account",
"_id": "472",
"_score": 5.4032025,
"_source": {
"account_number": 472,
"balance": 25571,
"firstname": "Lee",
"lastname": "Long",
"age": 32,
"gender": "F",
"address": "288 Mill Street",
"employer": "Comverges",
"email": "leelong@comverges.com",
"city": "Movico",
"state": "MT"
}
}]
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
# 测试案例2
@Test
void searchData() throws IOException {
// 创建检索请求
SearchRequest searchRequest = new SearchRequest();
// 指定索引
searchRequest.indices("bank");
// 指定DSL,检索条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("address", "mill"));
// searchSourceBuilder.from();
// searchSourceBuilder.size();
// 按照年龄的值分布聚合
TermsAggregationBuilder ageAgg = AggregationBuilders.terms("ageAgg")
.field("age").size(10);
searchSourceBuilder.aggregation(ageAgg);
// 按照年龄平均值聚合
AvgAggregationBuilder ageAvg = AggregationBuilders.avg("ageAvg").field("age");
searchSourceBuilder.aggregation(ageAvg);
// 按照薪资平均值聚合
AvgAggregationBuilder balanceAvg = AggregationBuilders.avg("balanceAvg").field("balance");
searchSourceBuilder.aggregation(balanceAvg);
System.out.println(searchSourceBuilder);
searchRequest.source(searchSourceBuilder);
// 执行检索
SearchResponse searchResponse = esClient.search(searchRequest, RequestOptions.DEFAULT);
// 分析结果
System.out.println(searchResponse.toString());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
- 条件构造
{
"query": {
"match": {
"address": {
"query": "mill",
"operator": "OR",
"prefix_length": 0,
"max_expansions": 50,
"fuzzy_transpositions": true,
"lenient": false,
"zero_terms_query": "NONE",
"auto_generate_synonyms_phrase_query": true,
"boost": 1.0
}
}
},
"aggregations": {
"ageAgg": {
"terms": {
"field": "age",
"size": 10,
"min_doc_count": 1,
"shard_min_doc_count": 0,
"show_term_doc_count_error": false,
"order": [{
"_count": "desc"
}, {
"_key": "asc"
}]
}
},
"ageAvg": {
"avg": {
"field": "age"
}
},
"balanceAvg": {
"avg": {
"field": "balance"
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
发现检索条件和自己写Query DSL很类似
- 结果
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 5.4032025,
"hits": [{
"_index": "bank",
"_type": "account",
"_id": "970",
"_score": 5.4032025,
"_source": {
"account_number": 970,
"balance": 19648,
"firstname": "Forbes",
"lastname": "Wallace",
"age": 28,
"gender": "M",
"address": "990 Mill Road",
"employer": "Pheast",
"email": "forbeswallace@pheast.com",
"city": "Lopezo",
"state": "AK"
}
}, {
"_index": "bank",
"_type": "account",
"_id": "136",
"_score": 5.4032025,
"_source": {
"account_number": 136,
"balance": 45801,
"firstname": "Winnie",
"lastname": "Holland",
"age": 38,
"gender": "M",
"address": "198 Mill Lane",
"employer": "Neteria",
"email": "winnieholland@neteria.com",
"city": "Urie",
"state": "IL"
}
}, {
"_index": "bank",
"_type": "account",
"_id": "345",
"_score": 5.4032025,
"_source": {
"account_number": 345,
"balance": 9812,
"firstname": "Parker",
"lastname": "Hines",
"age": 38,
"gender": "M",
"address": "715 Mill Avenue",
"employer": "Baluba",
"email": "parkerhines@baluba.com",
"city": "Blackgum",
"state": "KY"
}
}, {
"_index": "bank",
"_type": "account",
"_id": "472",
"_score": 5.4032025,
"_source": {
"account_number": 472,
"balance": 25571,
"firstname": "Lee",
"lastname": "Long",
"age": 32,
"gender": "F",
"address": "288 Mill Street",
"employer": "Comverges",
"email": "leelong@comverges.com",
"city": "Movico",
"state": "MT"
}
}]
},
"aggregations": {
"lterms#ageAgg": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [{
"key": 38,
"doc_count": 2
}, {
"key": 28,
"doc_count": 1
}, {
"key": 32,
"doc_count": 1
}]
},
"avg#ageAvg": {
"value": 34.0
},
"avg#balanceAvg": {
"value": 25208.0
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
# 返回结果封装JavaBean
在实际场景中,是需要返回到前端的,ES官方 (opens new window)也提供了方法,方便返回。
RestStatus status = searchResponse.status();
TimeValue took = searchResponse.getTook();
Boolean terminatedEarly = searchResponse.isTerminatedEarly();
boolean timedOut = searchResponse.isTimedOut();
2
3
4
TotalHits totalHits = hits.getTotalHits();
// the total number of hits, must be interpreted in the context of totalHits.relation
long numHits = totalHits.value;
// whether the number of hits is accurate (EQUAL_TO) or a lower bound of the total (GREATER_THAN_OR_EQUAL_TO)
TotalHits.Relation relation = totalHits.relation;
float maxScore = hits.getMaxScore();
2
3
4
5
6
返回结果封装:
Map map = JSON.parseObject(searchResponse.toString(), Map.class);
这样显然是不行的,因为从测试案例2中,发现里面封装了很多层,需要获取真实数据要很多层,而且返回到前端也是需要封装成JavaBean,所幸,可以使用官方文档提供的解决方法。
- 在测试案例2,添加实例代码:
// 分析结果
System.out.println("返回结果:");
System.out.println(searchResponse.toString());
// Map map = JSON.parseObject(searchResponse.toString(), Map.class);
// 获取素有查到的数据
SearchHits searchHits = searchResponse.getHits();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
Account account = JSON.parseObject(sourceAsString, Account.class);
System.out.println("account:"+account);
}
2
3
4
5
6
7
8
9
10
11
12
# 检索条件:
{"query":{"match":{"address":{"query":"mill","operator":"OR","prefix_length":0,"max_expansions":50,"fuzzy_transpositions":true,"lenient":false,"zero_terms_query":"NONE","auto_generate_synonyms_phrase_query":true,"boost":1.0}}},"aggregations":{"ageAgg":{"terms":{"field":"age","size":10,"min_doc_count":1,"shard_min_doc_count":0,"show_term_doc_count_error":false,"order":[{"_count":"desc"},{"_key":"asc"}]}},"ageAvg":{"avg":{"field":"age"}},"balanceAvg":{"avg":{"field":"balance"}}}}
# 返回结果:
{"took":3,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":4,"relation":"eq"},"max_score":5.4032025,"hits":[{"_index":"bank","_type":"account","_id":"970","_score":5.4032025,"_source":{"account_number":970,"balance":19648,"firstname":"Forbes","lastname":"Wallace","age":28,"gender":"M","address":"990 Mill Road","employer":"Pheast","email":"forbeswallace@pheast.com","city":"Lopezo","state":"AK"}},{"_index":"bank","_type":"account","_id":"136","_score":5.4032025,"_source":{"account_number":136,"balance":45801,"firstname":"Winnie","lastname":"Holland","age":38,"gender":"M","address":"198 Mill Lane","employer":"Neteria","email":"winnieholland@neteria.com","city":"Urie","state":"IL"}},{"_index":"bank","_type":"account","_id":"345","_score":5.4032025,"_source":{"account_number":345,"balance":9812,"firstname":"Parker","lastname":"Hines","age":38,"gender":"M","address":"715 Mill Avenue","employer":"Baluba","email":"parkerhines@baluba.com","city":"Blackgum","state":"KY"}},{"_index":"bank","_type":"account","_id":"472","_score":5.4032025,"_source":{"account_number":472,"balance":25571,"firstname":"Lee","lastname":"Long","age":32,"gender":"F","address":"288 Mill Street","employer":"Comverges","email":"leelong@comverges.com","city":"Movico","state":"MT"}}]},"aggregations":{"lterms#ageAgg":{"doc_count_error_upper_bound":0,"sum_other_doc_count":0,"buckets":[{"key":38,"doc_count":2},{"key":28,"doc_count":1},{"key":32,"doc_count":1}]},"avg#ageAvg":{"value":34.0},"avg#balanceAvg":{"value":25208.0}}}
account:ElasticsearchConfigTest.Account(account_number=970, balance=19648, firstname=Forbes, lastname=Wallace, age=28, gender=M, address=990 Mill Road, employer=Pheast, email=forbeswallace@pheast.com, city=Lopezo, state=AK)
account:ElasticsearchConfigTest.Account(account_number=136, balance=45801, firstname=Winnie, lastname=Holland, age=38, gender=M, address=198 Mill Lane, employer=Neteria, email=winnieholland@neteria.com, city=Urie, state=IL)
account:ElasticsearchConfigTest.Account(account_number=345, balance=9812, firstname=Parker, lastname=Hines, age=38, gender=M, address=715 Mill Avenue, employer=Baluba, email=parkerhines@baluba.com, city=Blackgum, state=KY)
account:ElasticsearchConfigTest.Account(account_number=472, balance=25571, firstname=Lee, lastname=Long, age=32, gender=F, address=288 Mill Street, employer=Comverges, email=leelong@comverges.com, city=Movico, state=MT)
2
3
4
5
6
7
8
# 返回结果分析信息
也可以,将这次检索到的分析信息,再进行遍历。
- 官方实例
Aggregations aggregations = searchResponse.getAggregations();
Terms byCompanyAggregation = aggregations.get("by_company");
Bucket elasticBucket = byCompanyAggregation.getBucketByKey("Elastic");
Avg averageAge = elasticBucket.getAggregations().get("average_age");
double avg = averageAge.getValue();
2
3
4
5
在返回的JSON数据中,可以看到某个聚合都是类似类型+聚合名字的格式,比如:lterms#ageAgg,avg#ageAvg,在Java中,可以直接获取聚合名字。
- 测试案例2,添加实例代码:
// 获取这次检索到的分析信息
// 年龄分布
Aggregations aggregations = searchResponse.getAggregations();
Terms ageAgg1 = aggregations.get("ageAgg");
for (Terms.Bucket bucket : ageAgg1.getBuckets()) {
String keyAsString = bucket.getKeyAsString();
System.out.println("年龄分布:" + keyAsString);
}
// 平均年龄
Avg ageAvg1 = aggregations.get("ageAvg");
System.out.println("平均年龄:" + ageAvg1.getValue());
// 平均薪资
Avg balanceAvg1 = aggregations.get("balanceAvg");
System.out.println("平均薪资:" + balanceAvg1.getValue());
2
3
4
5
6
7
8
9
10
11
12
13
14
- 输出结果
年龄分布:38 年龄分布:28 年龄分布:32 平均年龄:34.0 平均薪资:25208.0
# 总结
至此,对SpringBoot整合ES的操作,也初步掌握了,以后只要参照文档或者笔记,提高熟练度就可以得心应手了。如果有新的API需要去学习,只需要参照官方文档使用就行了。