 Web基础
Web基础
今天我们访问网站,使用App时,都是基于Web这种Browser/Server模式,简称BS架构,它的特点是,客户端只需要浏览器,应用程序的逻辑和数据都存储在服务器端。浏览器只需要请求服务器,获取Web页面,并把Web页面展示给用户即可。
Web页面具有极强的交互性。由于Web页面是用HTML编写的,而HTML具备超强的表现力,并且,服务器端升级后,客户端无需任何部署就可以使用到新的版本,因此,BS架构升级非常容易。
# HTTP协议
在Web应用中,浏览器请求一个URL,服务器就把生成的HTML网页发送给浏览器,而浏览器和服务器之间的传输协议是HTTP,所以:
- HTML是一种用来定义网页的文本,会HTML,就可以编写网页;
- HTTP是在网络上传输HTML的协议,用于浏览器和服务器的通信。
HTTP协议是一个基于TCP协议之上的请求-响应协议,它非常简单,我们先使用Chrome浏览器查看新浪首页,然后选择View - Developer - Inspect Elements就可以看到HTML:
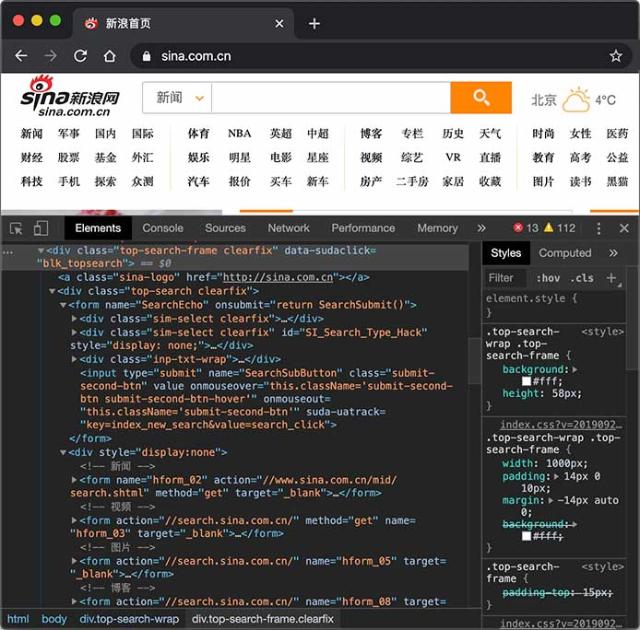
切换到Network,重新加载页面,可以看到浏览器发出的每一个请求和响应:
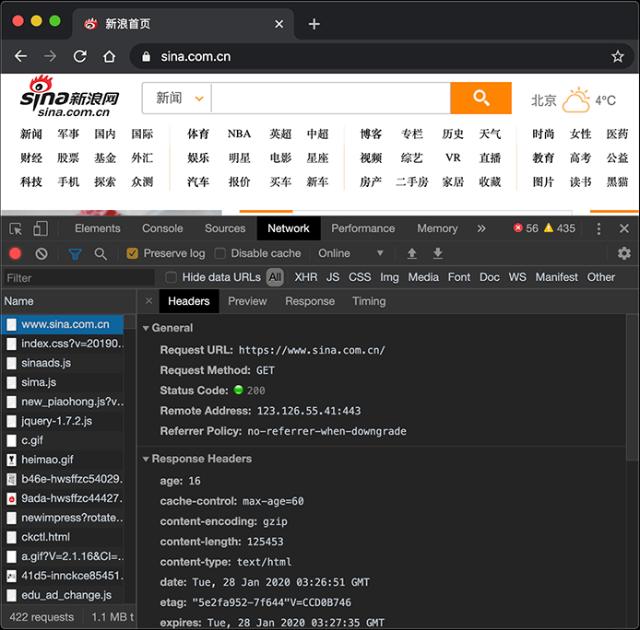
使用Chrome浏览器可以方便地调试Web应用程序。
# 请求页面的流程
对于Browser来说,请求页面的流程如下:
- 与服务器建立TCP连接;
- 发送HTTP请求;
- 收取HTTP响应,然后把网页在浏览器中显示出来。
# 请求
浏览器发送的HTTP请求如下:
GET / HTTP/1.1
Host: www.sina.com.cn
User-Agent: Mozilla/5.0 xxx
Accept: */*
Accept-Language: zh-CN,zh;q=0.9,en-US;q=0.8
2
3
4
5
其中,第一行表示使用GET请求获取路径为/的资源,并使用HTTP/1.1协议,从第二行开始,每行都是以Header: Value形式表示的HTTP头,比较常用的HTTP Header包括:
- Host: 表示请求的主机名,因为一个服务器上可能运行着多个网站,因此,Host表示浏览器正在请求的域名;
- User-Agent: 标识客户端本身,例如Chrome浏览器的标识类似
Mozilla/5.0 ... Chrome/79,IE浏览器的标识类似Mozilla/5.0 (Windows NT ...) like Gecko; - Accept:表示浏览器能接收的资源类型,如
text/*,image/*或者*/*表示所有; - Accept-Language:表示浏览器偏好的语言,服务器可以据此返回不同语言的网页;
- Accept-Encoding:表示浏览器可以支持的压缩类型,例如
gzip, deflate, br。
# 响应
服务器的响应如下:
HTTP/1.1 200 OK
Content-Type: text/html
Content-Length: 21932
Content-Encoding: gzip
Cache-Control: max-age=300
<html>...网页数据...
2
3
4
5
6
7
服务器响应的第一行总是版本号+空格+数字+空格+文本,数字表示响应代码,其中2xx表示成功,3xx表示重定向,4xx表示客户端引发的错误,5xx表示服务器端引发的错误。数字是给程序识别,文本则是给开发者调试使用的。常见的响应代码有:
- 200 OK:表示成功;
- 301 Moved Permanently:表示该URL已经永久重定向;
- 302 Found:表示该URL需要临时重定向;
- 304 Not Modified:表示该资源没有修改,客户端可以使用本地缓存的版本;
- 400 Bad Request:表示客户端发送了一个错误的请求,例如参数无效;
- 401 Unauthorized:表示客户端因为身份未验证而不允许访问该URL;
- 403 Forbidden:表示服务器因为权限问题拒绝了客户端的请求;
- 404 Not Found:表示客户端请求了一个不存在的资源;
- 500 Internal Server Error:表示服务器处理时内部出错,例如因为无法连接数据库;
- 503 Service Unavailable:表示服务器此刻暂时无法处理请求。
从第二行开始,服务器每一行均返回一个HTTP头。服务器经常返回的HTTP Header包括:
- Content-Type:表示该响应内容的类型,例如
text/html,image/jpeg; - Content-Length:表示该响应内容的长度(字节数);
- Content-Encoding:表示该响应压缩算法,例如
gzip; - Cache-Control:指示客户端应如何缓存,例如
max-age=300表示可以最多缓存300秒。
HTTP请求和响应都由HTTP Header和HTTP Body构成,其中HTTP Header每行都以\r\n结束。如果遇到两个连续的\r\n,那么后面就是HTTP Body。浏览器读取HTTP Body,并根据Header信息中指示的Content-Type、Content-Encoding等解压后显示网页、图像或其他内容。
通常浏览器获取的第一个资源是HTML网页,在网页中,如果嵌入了JavaScript、CSS、图片、视频等其他资源,浏览器会根据资源的URL再次向服务器请求对应的资源。
关于HTTP协议的详细内容,请参考HTTP权威指南 (opens new window)一书,或者Mozilla开发者网站 (opens new window)。
我们在前面介绍的HTTP编程 (opens new window)是以客户端的身份去请求服务器资源。现在,我们需要以服务器的身份响应客户端请求,编写服务器程序来处理客户端请求通常就称之为Web开发。