 数据结构简述
数据结构简述
# 概述
# 为什么要了解数据结构?
任何一个有志于从事IT领域的人员来说,数据结构(Data Structure)是一门和计算机硬件和软件都密切相关的学科,它的研究重点是在计算的程序设计领域中探讨如何在计算机中组织和存储数据并进行高效率的运用,涉及的内容包括:
- 数据的逻辑关系
- 数据的存储结构
- 排序算法(
Alegorithm) - 查找(或搜索)
- ……等等
我们举一个形象的例子来理解数据结构的作用:

战场:程序运行所需的软件、硬件环境。
敌人:项目或模块的功能需求
指挥官:编写程序的程序员
士兵和装备:一行一行的代码
战术和策略:数据结构

如果没有数据结构,也就是没有战术和策略,打仗事倍功半,也就是开发程序事倍功半,程序运行也是事倍功半。

如果有数据结构,有战术和策略,打仗事半功倍,也就是开发程序事半功倍,程序运行也是事半功倍。
简单来说,数据结构就是一种程序设计优化的方法论,研究数据的逻辑结构和物理结构以及它们之间的相互关系,并对这种结构定义响应的运算,目的是加快程序的执行速度、减少内存占用的空间。
因此,数据结构和算法是一名程序开发人员的必备基本功,不是一朝一夕就能练成绝世高手的。冰冻三尺非一日之寒,需要我们平时不断的主动去学习积累。
# 场景
计算机的主要工作就是把数据(Data)经过某种运算处理转换为使用的信息(Information)。具体介绍一些数据结构的应用:
- 1、树形结构
属性结构是一种相当重要的非线性数据结构,广泛运用在人类社会的族谱、机关的组织结构、计算机的操作系统结构、平面绘图应用、游戏设计等方面。
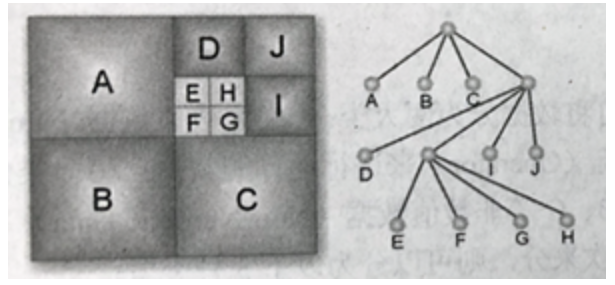
上图:四叉树示意图
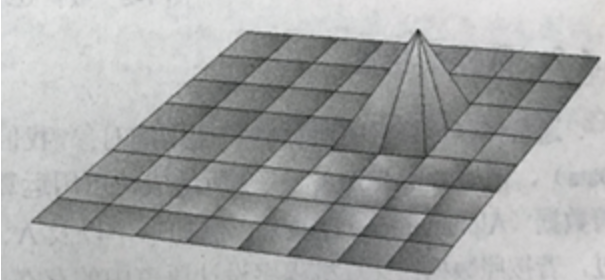
上图:地形与四叉树的对应关系
- 2、最短路径
最短路径是指在众多不同的路径中距离最短或者所花费成本最少的路径。寻找最短路径最常见的应用是公共交通运输系统的规划或网络的假设,如都市公交系统、铁路运输系统、通信网络系统等。
现在很多汽车和手机都安装了GPS导航,用于定位和路况查询。其中路程的计算是以最短路径的理论作为程序设计的一句,为旅行者提供不同的路径作为选择方案。
- 3、搜索理论
所谓“搜索引擎”,是一种自动从因特网的众多网站中查找信息,再经过一定的整理后提供给用户进行查询的系统,例如谷歌、百度、搜狗等搜索引擎。
注意,Search这个单词在网络上习惯范围为“搜索”,如搜索疫情。而在数据结构的算法描述中,习惯翻译成“查找”。在计算机科学中,“搜索”和“查找”大部分情况下可以互相转换。
Pascal之父Nicklaus Wirth: “Algorithms+Data Structures=Programs”
上面我们提到的数据结构和算法是程序设计实践中最基本的内涵。**程序能否快速而高效地完成预定的任务,取决于是否选对了数据结构,而程序是否能清楚而正确地把问题解决,则取决于算法。**算法是计算机处理信息的本质,因为计算机程序本质上是一个算法来告诉计算机确切的步骤来执行一个指定的任务。
所以大家认为:“Algorithms + Data Structures = Programs”(出自:Pascal之父Nicklaus Wirth)
数据结构只是静态的描述了数据元素之间的关系。
高效的程序需要在数据结构的基础上设计和选择算法。
总结:算法是为了解决实际问题而设计的,数据结构是算法需要处理的问题载体。
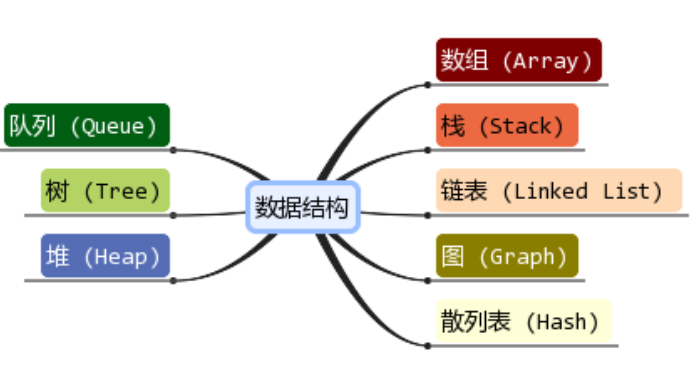
# 数据结构的研究对象
# 数据间的逻辑结构
数据的逻辑结构指反映数据元素之间的逻辑关系的数据结构,其中的逻辑关系是指数据元素之间的前后件关系,而与他们在计算机中的存储位置无关。
逻辑结构包括:集合结构、线性结构、树形结构、图形结构。
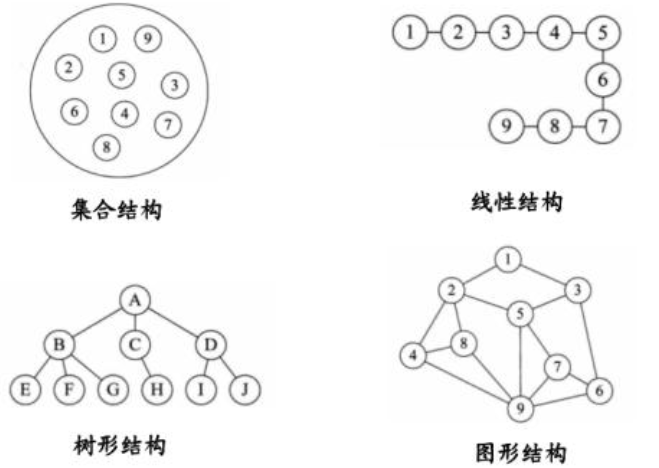
- 集合:数据元素之间只有“同属于一个集合”的关系
- 线性关系:数据元素之间存在一个对一个的关系,对应Java中的线性表:顺序表、链表、栈、队列。
- 树形结构:数据元素之间存在一个对多个的关系,对应Java中的树。比如:二叉树
- 网状结构(或图状结构):数据元素之间存在多个对多个的关系,对应Java中的图
# 数据的存储结构(或物理结构)
数据的存储结构(或物理结构)指数据的逻辑结构在计算机存储空间的存放形式。
数据的存储结构是数据结构在计算机中的表示(又称映像),它包括数据元素的机内表示和关系的机内表示。由于具体实现的方法有顺序、链接、索引、散列等多种,所以,一种数据结构可表示成一种或多种存储结构。
数据元素的机内表示(映像方法): 用二进制位(bit)的位串表示数据元素。通常称这种位串为节点(node)。当数据元素有若干个数据项组成时,位串中与个数据项对应的子位串称为数据域(data field)。因此,节点是数据元素的机内表示(或机内映像)。
**关系的机内表示(映像方法):**数据元素之间的关系的机内表示可以分为顺序映像和非顺序映像,常用两种存储结构:顺序存储结构和链式存储结构。顺序映像借助元素在存储器中的相对位置来表示数据元素之间的逻辑关系。非顺序映像借助指示元素存储位置的指针(pointer)来表示数据元素之间的逻辑关系。
# 真实结构
在内存中真实存在的, 用来存放多个数据的内存结构。
# 静态数据结构
线性表之顺序表(或静态数据结构):数组(Array)、ArrayList
特点:① 使用连续分配的内存空间;②一次申请一大段连续的空间, 需要事先声明最大可能要占用的固定内存空间
优点:设计简单,读取与修改表中任意一个元素的时间都是固定的
缺点:① 容易造成内存的浪费;② 删除或插入数据需要移动大量的数据
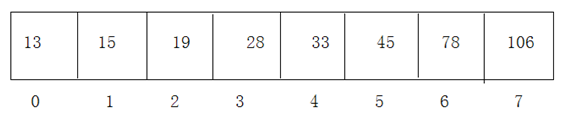
# 存储思路
- 所有数据存储在这个连续的空间中
- 数组中的每一个元素都是一个具体的数据
- 所有数据都紧密排布,不能有间隔
- 图示
# 操作
- 读内存:查:每个元素都有一个数值下标, 可以通过下标瞬间定位到某个元素
- 写内存:
- 增:
- 从头部插入
- 在中间插入
- 从尾部插入
- 注意:插入元素,引起部分元素后移,代价非常高
- 删:注意:去掉元素,引起部分元素前移,代价非常高
- 改:注意:只需要修改对应位置的元素的内容,不需要申请或者删除空间
- 增:
# 适用范围
- 查询操作远多于插入/删除操作的场景
- 简单抽象数据结构的基石
# 动态数据结构
线性表之链表(或动态数据结构):Linked List
- 特点:① 使用不连续的内存空间;② 不需要提前声明好指定大小的内存空间。一次申请一小块内存,按需申请
- 优点:① 充分节省内存空间;② 数据的插入和删除方便,不需要移动大量数据
- 缺点:① 设计此数据结构较为麻烦;② 查找数据必须按顺序找到该数据为止,麻烦
# 存储思路
每一个小数据单独存在一小块内存中,这个单元被称作结点(Node)
每一小块内存知道下一小块的地址
多个不连续的小内存空间组成, 通过内存地址引用形成一个链的结构
图示
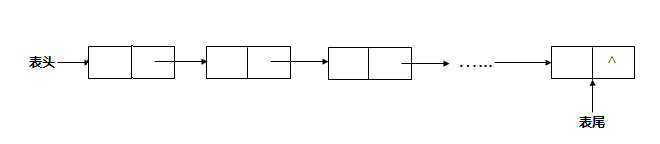
- 表头:程序员获得表头就可以找到链表中所有的元素
- 表尾:有的链表有,有的没有
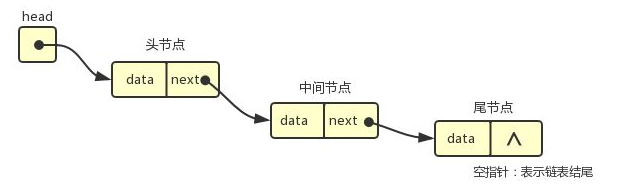
# 实现结构:链表
- 单向链表
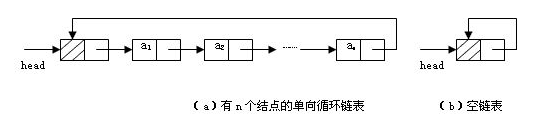
- 环形链表
- 双向链表
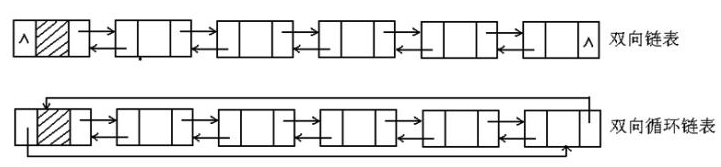
# 读写操作
- 读
- 查
- 节点是没有下标的, 只能从链表的表头开始查找某个节点
- 查
- 写
- 增
- 申请一小块内存--结点
- 插入到链中
- 从头部插入
- 从尾部插入
- 从中间插入
- 删
- 从链中剥离结点
- 释放这个结点的内存
- 改
- 改变这个结点中所存储的值
- 增
# 适用范围
- 插入/删除操作远多于查询操作的场景
- 复杂抽象数据结构的基石
# 抽象结构(ADT)
# 栈(Stack)
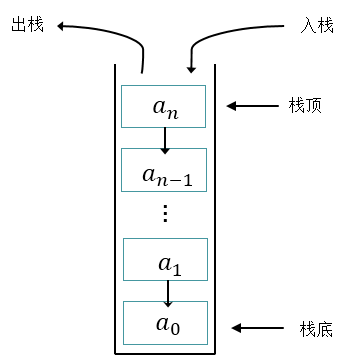
栈(Stack)是限制仅在表的一端进行插入和删除运算的线性表。
栈的修改原则:
栈的修改是按后进先出的原则进行。每次删除(退栈)的总是当前栈中"最新"的元素,即最后插入(进栈)的元素,而最先插入的是被放在栈的底部,要到最后才能删除。

超市货架上的商品
一叠书
# 概念
- 栈顶:插入、删除的这一端为栈顶
- 栈底:相对于栈顶的另一端
- 空栈:当表中没有元素时称为空栈
# 特点
- 继承于java.util.Vector
- 后进先出
# 实现结构
顺序表实现栈
- 用数组实现
- 优点:算法简单
- 缺点:数组大小只能事先规划声明好,太大了浪费空间,太小了不够用
链表实现栈
- 优点:随时可动态改变链表长度,有效利用内存空间
- 缺点:算法设计复杂
# 基本运算
- 进栈(压栈、入栈): push(ele)
- 出栈: pop()
- 查看栈顶元素: peek()
- 清栈: clear()
- 大小: size()
- 判断是否是空:empty()
- 查找元素出现位置:search(Object obj)
# 使用场景
- 二叉树和森林的遍历
- CPU的中断处理
- 图形的深度优先查找法(DFS)
- 递归调用
- 斐波那契数列
- 汉诺塔问题
- 子程序的调用
# 队列(Queue)
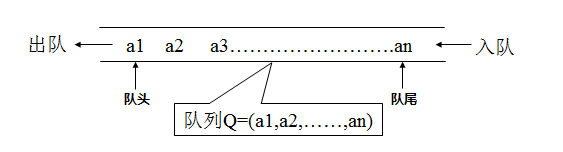
队列(Queue)是只允许在一端进行插入,而在另一端进行删除的运算受限的线性表。
队列的修改原则:
队列的修改是依先进先出的原则进行的。新来的成员总是加入队尾(即不允许"加塞"),每次离开的成员总是队列头上的(不允许中途离队),即当前"最老的"成员离队。

# 概念
- 队头(front):允许删除的一端称为队头(Front)
- 队尾(rear):允许添加的一端称为队尾(Rear)
- 空队列:当队列中没有元素时称为空队列
# 特点
- 先进先出
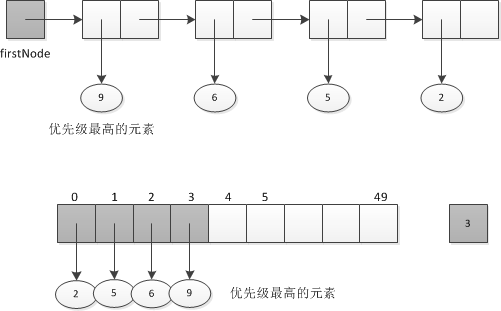
- 典型实现:PriorityQueue
# 实现结构
顺序表实现队列
- 用数组实现
- 优点:算法简单
- 缺点:数组大小固定,无法根据队列实际需要动态申请
链表实现队列
- 优点:随时可动态改变链表长度,有效利用内存空间
- 缺点:算法设计复杂
# 操作
- 加入元素到队列尾部: add(Object obj)/offer(Object obj)
- 获取队列头部元素,不删除该元素:element()/peek()
- 获取队列头部元素,并删除该元素:remove()/poll()
- 清理队列: clear()
- 得到队列的大小: size()
- 判断队列是否是空的: isEmpty()
# 使用场景
- 图形的广度优先查找法(BFS)
- 可用于计算机各种事件处理的模拟
- 如: 事件队列, 消息队列
- CPU的作业调度
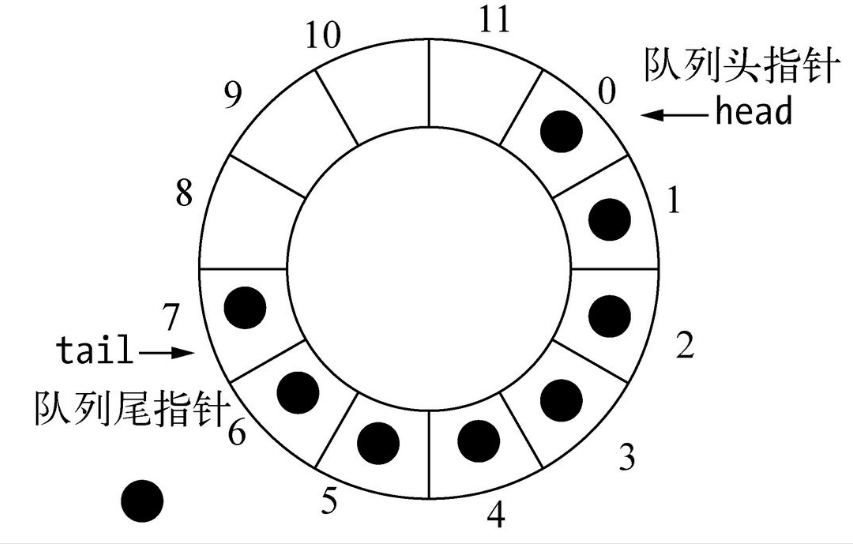
# 变形的队列
- 环形队列
- 双向队列
- 优先队列
# 树(Tree)
树:
对大量的输入数据,链表的线性访问时间太慢,不宜使用。这里是另外一种重要的数据结构----树,其大部分时间可以保证操作的运行平均时间复杂度为O(logN)。

公司组织架构
家族族谱
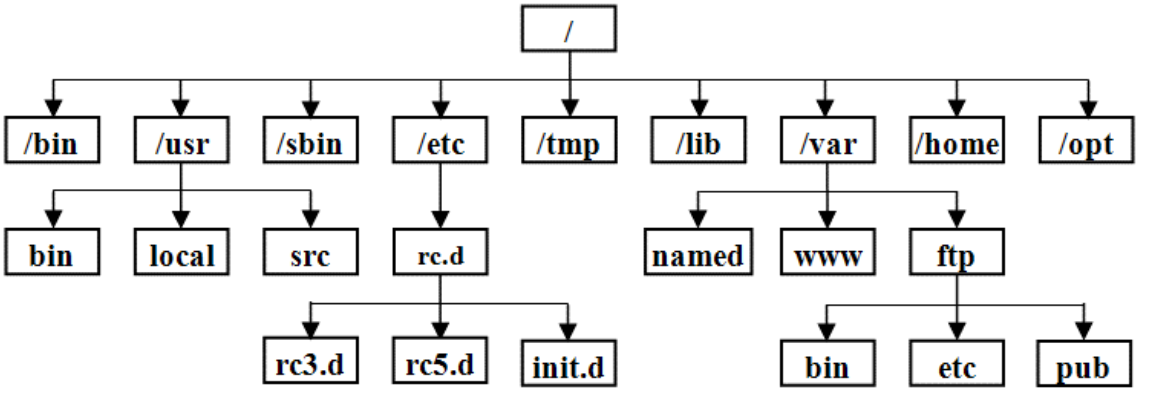
Linux系统的文件和目录结构
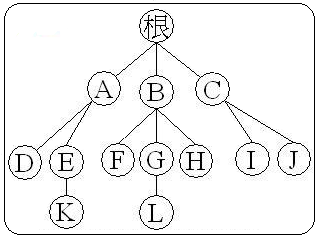
计算机世界的树
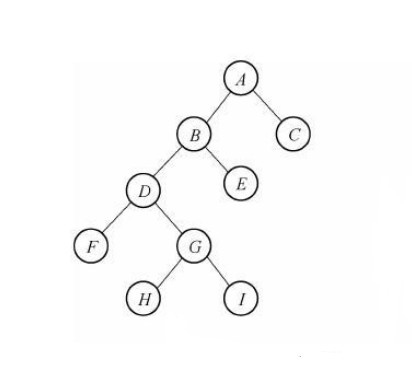
# 专有名词
- 结点:树中的数据元素都称之为结点
- 根节点:最上面的结点称之为根,一颗树只有一个根且由根发展而来,从另外一个角度来说,每个结点都可以认为是其子树的根
- 父节点:结点的上层结点,如图中,结点K的父节点是E、结点L的父节点是G
- 子节点:节点的下层结点,如图中,节点E的子节点是K节点、节点G的子节点是L节点
- 兄弟节点:具有相同父节点的结点称为兄弟节点,图中F、G、H互为兄弟节点
- 结点的度数:每个结点所拥有的子树的个数称之为结点的度,如结点B的度为3
- 树叶:度数为0的结点,也叫作终端结点,图中D、K、F、L、H、I、J都是树叶
- 非终端节点(或分支节点):树叶以外的节点,或度数不为0的节点。图中根、A、B、C、E、G都是
- 树的深度(或高度):树中结点的最大层次数,图中树的深度为4
- 结点的层数:从根节点到树中某结点所经路径上的分支树称为该结点的层数,根节点的层数规定为1,其余结点的层数等于其父亲结点的层数+1
- 同代:在同一棵树中具有相同层数的节点
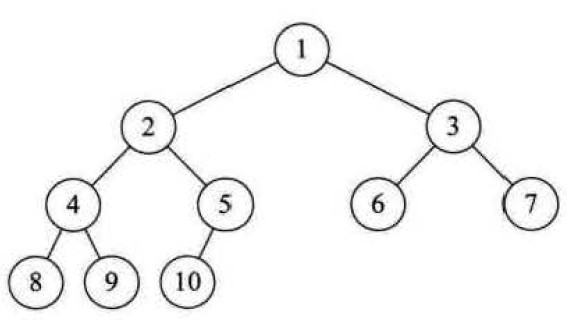
# 二叉树(Binary Tree)
二叉树:
在普通树的基础上,让一棵树中每个节点最多只能包含两个子节点,且严格区分左子节点和右子节点(位置不能换)。
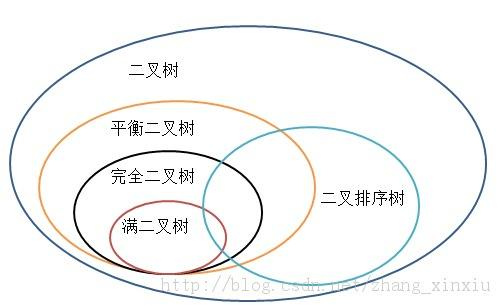
分类
功能
- 增删改查
- 搜索
- 广度优先搜索
- 深度优先搜索
- 前序遍历:树根->左子树->右子树
- 中序遍历:左子树->树根->右子树
- 后序遍历:左子树->右子树->树根
特例
排序二叉树
满足一些条件的二叉树,才被称为排序二叉树。比如:若它的左子树不为空,左子树上的所有节点
值均小于根节点值;若右子树不为空,右子树上的所有节点值均大于根节点值。
特点:可以非常方便地对树中的所有节点进行排序和检索。
红黑树
- 红黑树顾名思义就是结点是红色或者黑色的平衡二叉树,它通过颜色的约束来维持着二叉树的平衡。下图为一颗典型的二叉。
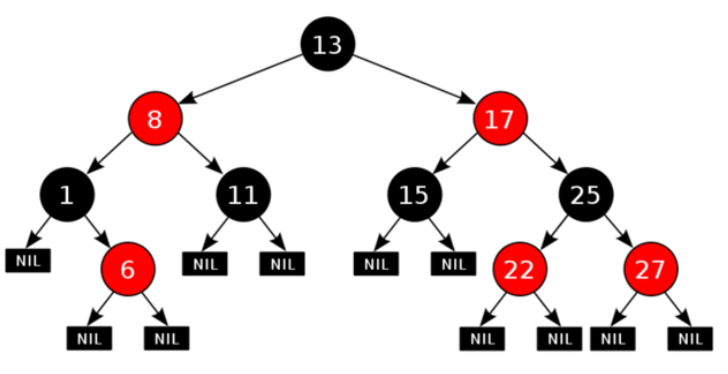
对于一棵有效的红黑树而言我们必须增加如下规则:
- 1、每个结点都只能是红色或者黑色
- 2、根节点是黑色
- 3、每片叶子都是黑色的
- 4、如果一个结点是红色的,则它的两个子节点都是黑色的,也就是说在一条路径上不能出现相邻的两个红色结点
- 5、从任意一个结点到其每个叶子的所有路径都包含着相同数目的黑色结点
这些约束强制了红黑树的关键性质:从根到叶子的最长的可能路径不多于最短的可能路径的两倍长。结果就是这棵树大致上是平衡的,因为插入、删除和查找某个值得最坏情况时间都要求与树的高度成比例,这个高度理论上限允许红黑树只在最坏情况下都是高效的。
再具体就不说了,可以参看http://www.cnblogs.com/yangecnu/p/Introduce-Red-Black-Tree.html,对红黑树的讲解写得非常好。
TreeMap和TreeSet就是红黑树的典型实现。
使用场景
- 哈夫曼树
- 一种带权路径最短的二叉树,在信息检索中很常用
- 哈夫曼编码
- 假设需要对一个字符串如“abcdabcaba”进行编码,将它转换为唯一的二进制码,同时要求转换出来的二进制码的长度最小。我们采用哈夫曼树来解决报文编码问题。
- **1. 哈夫曼编码:**在数据通信中,需要将传送的文字转换成二进制的字符串,现要求为这些字母设计编码。在实际应用中,各个字符的出现频度或使用次数是不相同的,如A、B、C的使用频率远远高于X、Y、Z,自然会想到设计编码时,让使用频率高的用短码,使用频率低的用长码,以优化整个报文编码。为了获得传送报文的最短长度,可将每个字符的出现频率作为字符结点的权值赋予该结点上,显然字使用频率越小权值越小,权值越小叶子就越靠下,于是频率小编码长,频率高编码短,这样就保证了此树的最小带权路径长度效果上就是传送报文的最短长度。利用哈夫曼树来设计二进制的前缀编码,既满足前缀编码的条件,又保证报文编码总长最短。
- **2. 哈夫曼译码:**在通信中,若将字符用哈夫曼编码形式发送出去,对方接收到编码后,将编码还原成字符的过程,称为哈夫曼译码。
- B+树
# 图
# 定义
由“顶点”和“边”所组成的集合
# 分类
- 无向图
- 有向图
# 图的表示法
- 邻接矩阵法
- 邻接表法
- 邻接复合链表法
- 索引表格法
# 图的遍历
- 深度优先遍历
- 广度优先遍历
# 应用场景
- 最短路径搜索
- 拓扑排序
# 其它
散列表(Hash),堆(Heap)
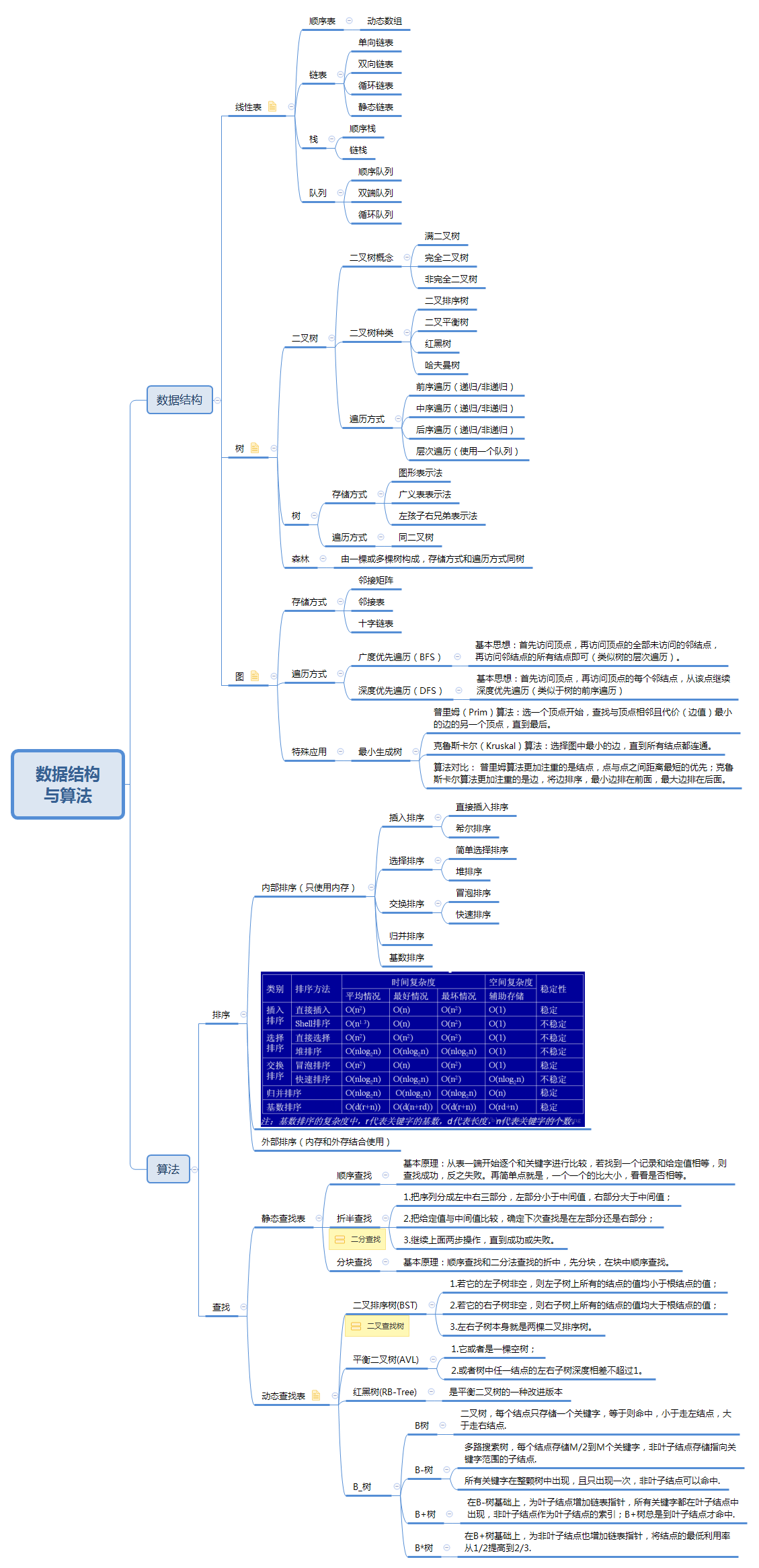
# 总结
# 参考书籍
数据结构与算法分析Java语言描述(第2版)[美] 卡拉罗(Carrano,F.M.) 著 金名,等 译

大话数据结构 (作 者:程杰 著)
